Why do we use a process?
A process…
- Puts everyone on the same page about how to proceed during a project
- Ensures everyone knows their roles and responsibilities
- Helps with onboarding of new employees
- Allows us to test and refine how we do things scientifically over time
- Increases efficiency
Every business, from restaurants to shipping companies, needs
processes to keep things running smoothly, and software consulting
companies are no exception. Having a well-defined process is not only
important in delivering products efficiently, but also as a part of
the sales process. Clients often ask about our process, and being able
to talk about it in detail shows we have thought it through and know
how to deliver products effectively.
The Cantina Process
The process that Cantina advertises on our website has the following steps:

This is a good description of the coarse phases of our overall process. However when we look at actually building the software using an agile methodology, we need to think in terms of iterations. It turns out that these steps also translate quite nicely into iterations if we think about the process as a continuous cycle:
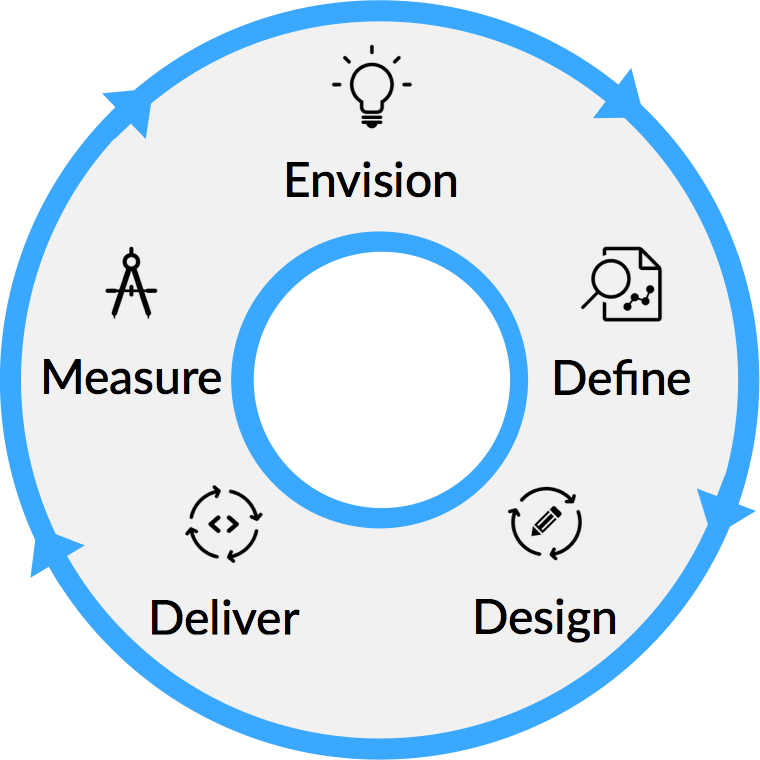
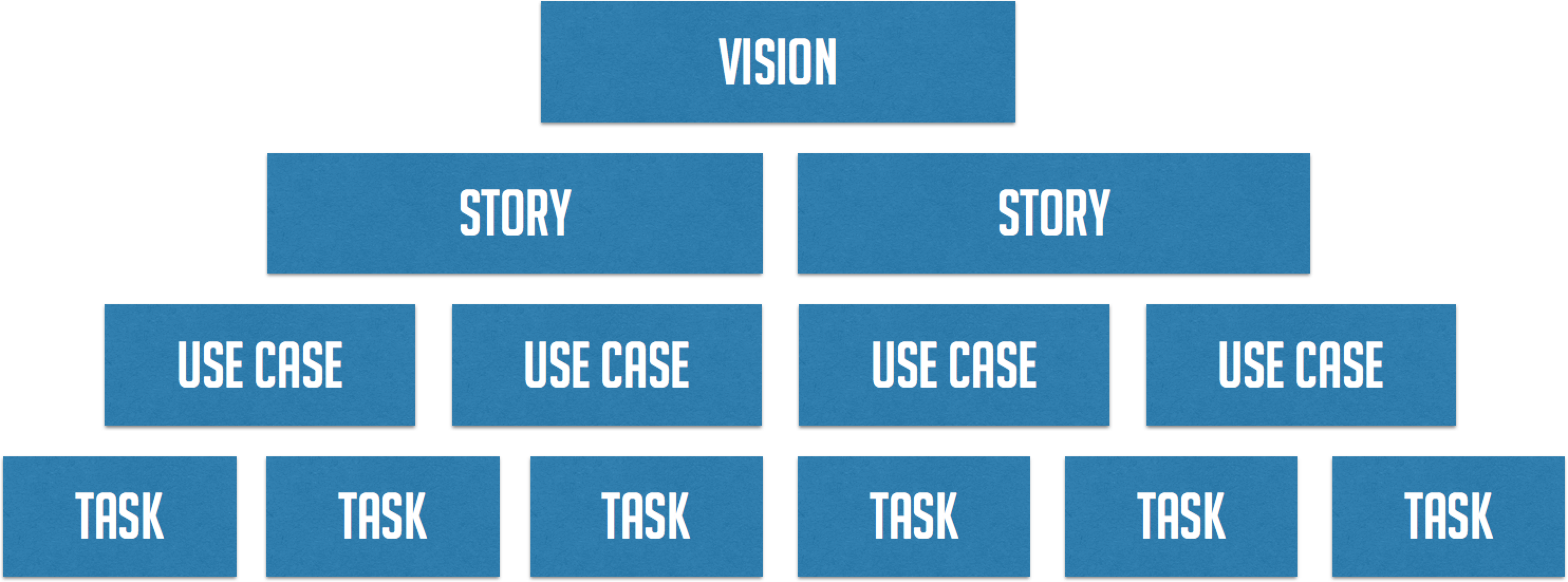
As each of the phases of the process are completed, there is concrete output that eventually results in working software. If we look at those outputs, they form a tree, from the vision of the product all the way down to tasks that will be performed to create the working product.
Envision
 The first step is Envision. Typically this happens before development begins. In this stage, we work with the client to determine the overall vision of the product using a variety of techniques like:
The first step is Envision. Typically this happens before development begins. In this stage, we work with the client to determine the overall vision of the product using a variety of techniques like:
- Industry research
- Documentation review
- Stakeholder interviews
- Collaborative workshops
This phase is very important not only to refine what the client wants from the product, but to get everyone on the team to understand why we are building it. If we can get everyone on board, it will be much easier to maintain motivation throughout the course of the project. If we understand the vision, we can really get behind the product and feel proud of what we’ve built.
Define
 Once we have the vision of the product, we can start to narrow down what the concrete goals are to be accomplished with the product. These goals are described with User Stories. The term User Story is quite overloaded in the industry, so let’s look at what Cantina means by the term.
Once we have the vision of the product, we can start to narrow down what the concrete goals are to be accomplished with the product. These goals are described with User Stories. The term User Story is quite overloaded in the industry, so let’s look at what Cantina means by the term.
What is a user story?
A User Story is a goal a user wants to accomplish and a rationale for why:
- Who? The type of user using the particular feature
- What? The goal they will accomplish with the feature
- Why? Why do they want to accomplish this goal?
An example of a user story might be: “As an editor, I want to approve articles before they are published so that I can ensure they meet our publishing guidelines”
Notice that the story doesn’t talk about anything implementation specific. We are trying to get at the real world goals that the user has, not specific features or how they will do it. That comes later. One reason for this is it helps the client take a step back from concrete features and think of the real reasons for the product’s existence. The rationale is an important part of the story. If the client has a hard time enunciating why a user might want to do something, the story is probably a good candidate to remove from scope. Reducing scope reduces time to market and risk.
One difference between this type of story and others you may have encountered is that Cantina doesn’t have a full staff of developer/designer unicorns, and that’s OK. We will have multiple people from a variety of disciplines working on a particular story at the same time. Also, there will be multiple ways that the goal might be accomplished in the application. This will become clearer in the next phase.
Design
 Once we have the goals we want to accomplish in the product, we can start to design how those goals will be accomplished and also start thinking about the technical aspects of the product.
Once we have the goals we want to accomplish in the product, we can start to design how those goals will be accomplished and also start thinking about the technical aspects of the product.
It’s important for the design team to have a bit of a head start so that the development team can have a decent backlog to work with. During the time the design team is designing the user experience, the development team can start to determine what the minimal technical design and stack might be and start setting up the development tools and processes.
Technical Design
One of the reasons Cantina uses the term “technical design” over “technical architecture” is that architecture is a loaded term with some negative connotations in the industry. Architecture implies a lot of up front planning and careful specification. In the brick and mortar world, this makes sense, because it is often very costly to change a building once it’s built. This isn’t true for software, however, if it’s done right. If we create clear boundaries in our software where it is expected to change, and use good programming practices, we can build a system where the technical design can change and be refined as we learn more about the technical requirements.
The Last Responsible Moment
The Last Responsible Moment is a term from lean software development. It means deferring important or difficult to change decisions until it’s irresponsible to do so. Essentially, this is when the potential cost of putting off the decision becomes greater than the cost of making the decision. For us, this can be things like deciding on a particular 3rd party provider or a particular database or middleware. One way of doing this is using temporary solutions for common components. For example, using an in-memory or embedded database, or using a simple in-process messaging implementation instead of specific middleware. By putting boundaries in place at these components, we can build the rest of the system without deciding on the final, concrete implementations. Deferring these important decisions until we have all the available information allows us to avoid making risky decisions that might be very costly to change later. Though there may be a small amount of work to implement these temporary components, the amount of reduced risk may be worth it.
Stack and Development Pipeline
Determining the stack and development pipeline entails things like deciding on languages, a toolchain, and setting up source control, continuous integration, and continuous deployment. It’s essential that these things are set up before development begins, or it will continuously degrade productivity and end up putting development on hold later when the team finally gets around to it, if they do it at all. Cantina considers a full, modern development pipeline to be the bare minimum on projects. It is something we expect our clients to provide if we are using their infrastructure. At a minimum we require the following:
- Continuous integration
- Test runner
- Style checking (linting)
- Code coverage
- Documentation generation
- Performance analysis (optional on a per-project need)
- Logging
- Continuous deployment
These systems will become important later in the Delivery and Measurement phases of the process.
Use Cases
The design team can use whatever methods they find to be more effective when designing the user experience. This can be anything from Jobs to be Done, to prototyping, to user testing. What’s important is the output of this phase, which is Use Cases.
The Use Case is one of the most important outputs of the design phase, as it drives the rest of the process. A Use Case is:
- A complete description of what will be built
- A complete description of what will be tested
- A complete description of what will be demoed
- The “definition of done” for the client to sign off on
If we look at an application as a single entity, from client to server to data layer and external services, we can see that every interaction follows the same pattern:
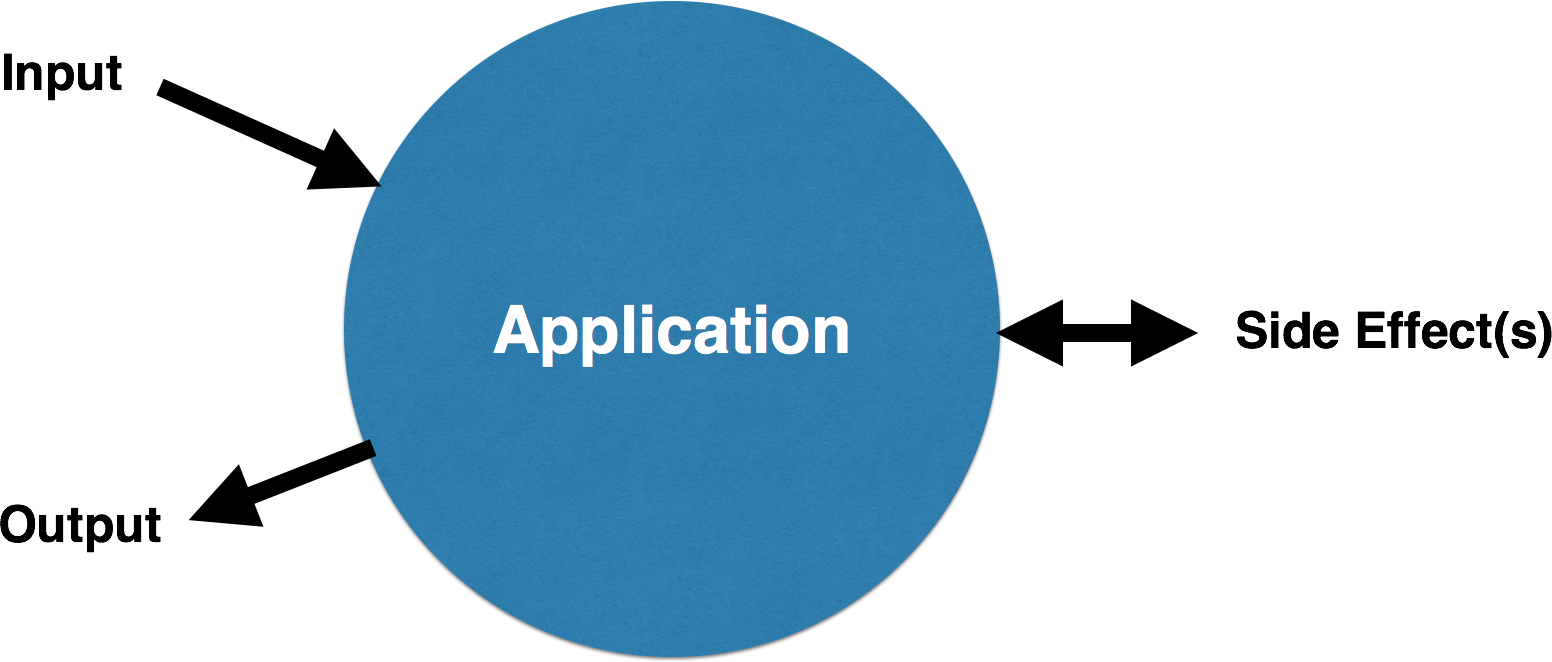
Before the interaction, we consider the application to be in a particular state. We call this the preconditions of the interaction. Next, there is some input into the application. This can be filling out a field on a form, sending request to an API, turning a knob, really anything. It’s possible that the application simply transforms this data and returns it, but more likely there are one or more side effects. Side effects are things like inserting data into a database or reading a file. Finally, there is some output from the application. This is usually some change to the user interface, but can really be any output, such as a JSON response from an API. Finally, after the interaction, the application is in a new state. We call this the postconditions of the interaction. This is a very functional view of an interaction and is often described as “design by contract”.
To review, Use Cases are interactions between the user and the application that achieves the goal of the story. They have the following components:
- Pre-conditions: The relevant state of the application before the interaction
- Input: The information transferred into the application from the interaction
- Side effect(s): The side effect(s) which occur
- Output: How the application responds to the user
- Post-conditions: The state of the application which was affected
Example Use Case
A simple example of a formatted Use Case might be:
Pre-conditions
An account with the email “dave@cantina.co” and password “12345” exists
Steps
- Authenticate with email “dave@cantina.co” and password “12345”
- Navigate to account form
- Enter “dfox@cantina.co” into email field
- Tap “save”
- Assert the “account updated” message appears
Post-conditions
- The account has been updated to use the email “dfox@cantina.co”
The corresponding story for this use case might be: “As a registered user, I want to be able to change the email on my account so that I can still receive alerts if I want to use a different address”
This textual description is added to the project tracking software that the developers will use during development. Along with this description, the designers might include prototypes, storyboards, whiteboard captures, or any other assets which will help the developers build out the use case. The more clear the Use Case is, the less churn there will be between the teams and the more efficient we will be. This doesn’t mean that the designers and developers don’t communicate, however. There should always be good communication between all team members during a project. We don’t just “throw it over the fence” and hope it gets built.
Who Writes the Use Case?
This is really part of a BA role, however more often, the developers will do this as a group. They will work with the designers and look at the prototypes, whiteboard captures, etc., discuss the interactions, and write out the use cases during grooming. This ensures that the developers themselves agree that each Use Case has enough information in it to be properly implemented.
Tasks
Once the team has the Use Cases, they can start to collaboratively determine what tasks are necessary to actually build them out. Tasks are the specific, concrete work everyone will perform to actually create the application. This should be done during sprint planning as a team so that everyone can have input. The technical designer should have a good idea of the components involved but it’s important for the members with varying disciplines to weigh in. Examples of tasks are:
- Create account_details database table
- Write UI test
- Stub controller method to return account details JSON
- Create service function to update email address on account details
- Create account details form
It’s also important here for the Technical Designer to help suggest assignments for tasks so that the work can be done in the most parallel fashion to gain the most efficiency.
Once the planning is done, the team moves into delivery.
Deliver
 For source control, Cantina has standardized on Git via GitHub and uses the full Gitflow process.
For source control, Cantina has standardized on Git via GitHub and uses the full Gitflow process.
Ideally the team will have, at minimum, a staging environment, a development environment, and a test environment that are able to be automatically deployed to. These environments must be as close to identical as possible, save their configration. The CI server will run tests against the test environment. The team will use the development environment to deploy builds as the team integrates with the develop branch, and when those are deemed stable enough they can be promoted to the staging environment by merging into master. Demos to the client are done from the staging environment which should always be stable. This allows the client to interact with the application as needed and possibly to have a Q/A team involved.
Test Driven Development
Cantina uses a full test driven development methodology. Testing is extremely important in delivering quality software. Some of the reasons for testing include:
- Proving that a Use Case works as described
- Flagging regressions before they make it into the staging environment
- Confident refactoring of technical debt, especially with dynamic languages like Javascript, Python, Ruby, etc.
- Less time spent debugging
- Testable software is generally better structured
- Real, large, empirical studies done by Microsoft, IBM and others show that software with tests has fewer bugs. End of story.
To some, it seems like writing tests takes a lot of time away from “actual development”, however this couldn’t be further from the case. If we look at the alternatives, it’s easy to see that testing actually decreases development time. Consider the time that it takes to write a UI test for a single interaction. Let’s be conservative and say it takes a few hours. Now think of the time it takes when there is a single regression. First the bug is discovered, by manually testing the app. Then someone has to write up the steps to reproduce it. Then the developer has to stop working on new features and walk through the steps to verify the bug. Then the bug has to be fixed, merged, and deployed. Then the fix has to be verified. You can see how even with one regression, the time quickly adds up. With no test, that regression could pop up again, and we haven’t even touched on the other inefficiencies:

The real question is how can we test most effectively, or spend the least amount of time writing test code while getting the most benefit.
Cantina’s Testing Strategy
Cantina’s minimal testing strategy can be summed up as the following:
- Functional, full-system, integrated, UI-based testing of each Use Case
- Integration tests of all external components
- Full continuous integration to run tests regularly
- Developers add further tests at their discretion
- Tests are written first, then the code
UI-Based System Tests
These tests automate the interaction that the user has with the application. The tests are run against the fully integrated application on the test environment. There are no* mocks used. The test follows the steps outlined in the Use Case and validates the pre and post conditions. In addition, there are integration tests which validate that the systems which perform the side-effects work correctly.
UI tests are generally very slow to run as they require the full running application to be started with all fixtures to be in place. They have also been historically considered very fragile. We will generally only run them on the continuous integration server to overcome the slowness, however the fragility of the tests is really up to the developer. Where aspects of the tests are fragile (e.g. where the test has to change often as a result of UI changes), the developer should introduce boundaries to isolate the changing code. Also, by agreeing on some common sense conventions, using named selectors instead of DOM-location-dependent ones, and by adhering to general best practices, we can alleviate much of the historic problems with these tests. Also, newer libraries such as Nightwatch help make developing these tests much easier. You can see how the Use Case can easily translate into code in this example:
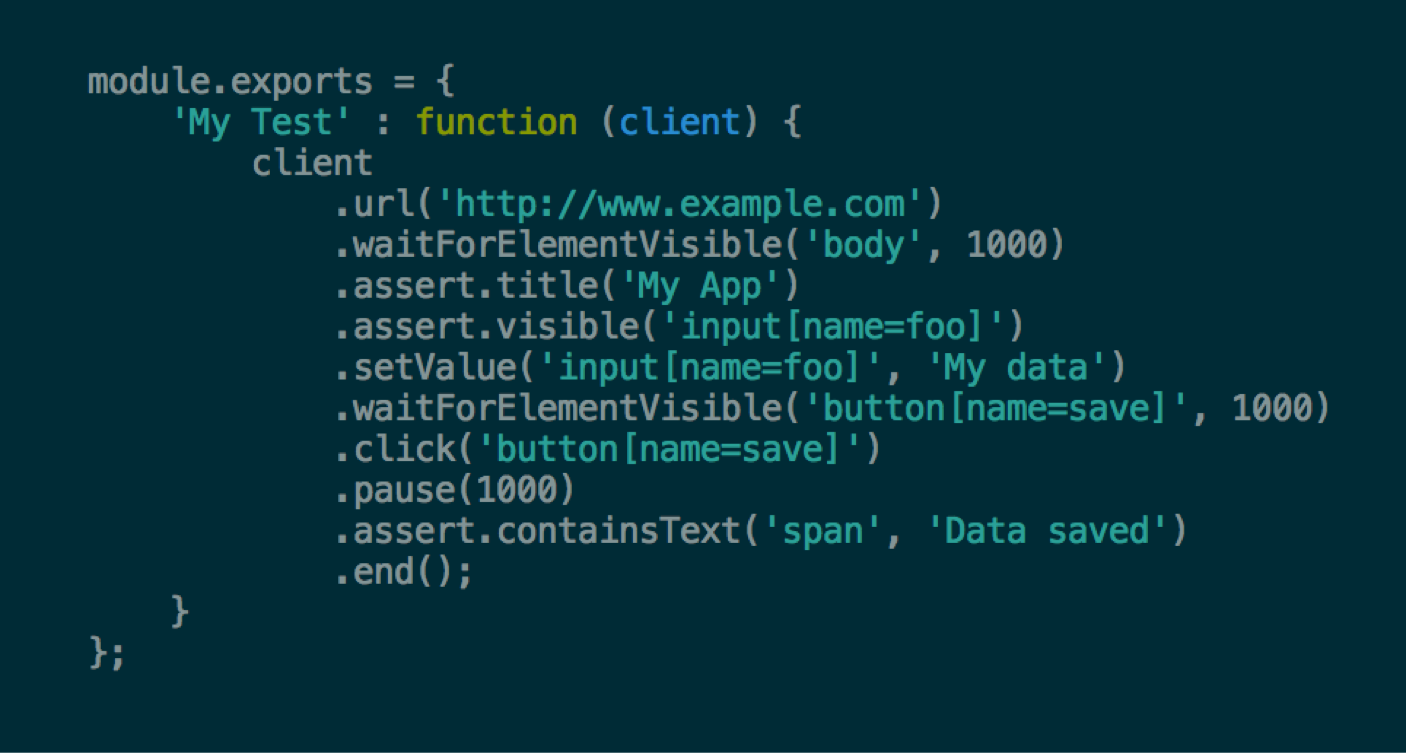
* Since we are running in a staging environment, some applications will make use of 3rd party services without the ability to run in “dev mode”. In these unfortunate circumstances, the staging environment may make use of mocked, or temporary gateway components.
iOS and Android
Unfortunately, the state of UI testing on iOS and Android is a little worse off. In projects where we have attempted this kind of testing, the available tools have made it very time consuming and error prone. Hopefully in the coming months, the testing libraries will mature to a usable state, or Cantina can invest some time in developing libraries to help us do UI testing more effectively.
Integration Tests
Like User Stories, the term “integration test” is also very overloaded. At Cantina, we consider an integration test to be one that validates how the application integrates with another system, be it a database, external service, or other component. For example, let’s say we are building a gateway that talks to an external web service. Our gateway has an API in the language of our internal domain, and translates that to HTTP calls to the web service. To ensure that this gateway does that translation correctly, we write an integration test for each API method on the gateway. Preferably, we do this by interacting with the real service which hopefully has a development mode. However, sometimes we can only assert that the calls are translated correctly into HTTP requests.
Walking Skeleton
 Once we have a test for a Use Case, we can start writing code. How do we begin? There is a concept from the book Growing Object Oriented Software, Guided by Tests that provides an answer. It’s called the Walking Skeleton.
Once we have a test for a Use Case, we can start writing code. How do we begin? There is a concept from the book Growing Object Oriented Software, Guided by Tests that provides an answer. It’s called the Walking Skeleton.
Essentially, what we do is decide on a “sketch” of the components involved in the Use Case interaction. The Technical Designer is essential here as they are aware of the overall design of the system and can help the developers determine the boundaries between the components and their APIs.
The developers then set about writing the components, but only as stubs. The developers will agree on the API conventions and make the appropriate calls with hard-coded return values to make the test pass as soon as possible. You can think of this as “fake it until you make it”. This ensures the component APIs are well defined and integration happens up front, before any other work is done. Once the components are integrated, the developers can work on the code independently knowing that then they merge their branches together, everything should “just work”. Although there will always be some issues with integration, this technique saves a lot of time and helps developers communicate better. So how does this play out in practice?

Let’s say you have 3 developers working on a Single Page Application with an API. One developer is working on the on the Javascript client, one on the HTTP API and service layer written in Java, and one on the data layer for the server, also written in Java. There are natural boundaries at the HTTP layer and at the data layer. There will be more inside the larger components, but for the purposes of the walking skeleton, we can concentrate on those.
If the JavaScript client developer and the API developer agree on the format of the request and the response, and stub those out, then the client and server will be integrated. There is no need to write down the JSON format on a wiki or some other documentation medium, just return a hard-coded response from the API. The code is the documentation. The developer working on the data layer can do the same thing, returning hard-coded objects to the service layer. The developers work together in the beginning until the components are integrated and the UI test passes. This work is then committed to a feature branch for the Use Case. Next, the developers can copy their own branches from that branch and work independently. When they are each done, they can merge into the feature branch.
The developer writing the client will write the UI test, knowing the UI components needed and how to access them most effectively. The server developer will write assertions for the side effects that occur, for example, in the database. We’ll discuss how to do that next.
Asserting Side Effects
One issue with traditional UI testing or “black box” testing is that a developer must implement both the read and the write side of an interaction in order to validate that the state of the application was updated. This means that there can be less incremental development as we must implement both sides before the test will pass. Also, it is sometimes not possible to validate the features of an application simply by exercising its UI. There is one testing strategy that can overcome these obstacles. Consider the following diagram:
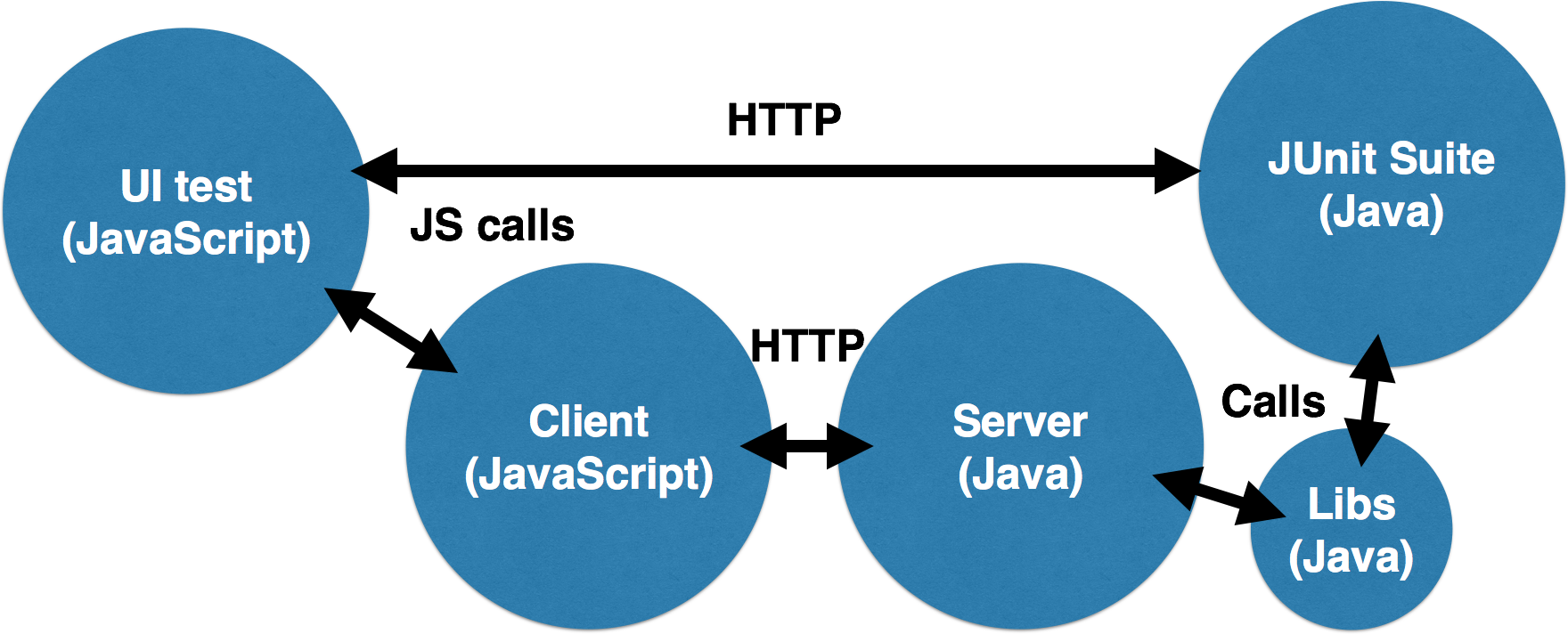
Let’s say that we are implementing a form that saves some data to a database. The UI test fills in the form and submits it using its headless browser. The JavaScript client then sends an HTTP request to the server which calls some Java libraries to save the data. How can the UI test code running in the headless browser assert that the information was saved? We can’t connect directly to the database from the browser (this is possible in some cases, but let’s say we can’t), and we wouldn’t want to re-implement the data access code again in JavaScript.
One way of accomplishing this is to write our database validation code in Java using something like JUnit. We then expose those tests to the UI test code via a simple HTTP API. The UI test code can then make a simple HTTP request to that API to execute the validation code. The JUnit suite can reuse the data layer code to perform the validation. Since the data layer code will have been tested via its own integration test, we can ensure the application functions correctly.
There is an aspect of “testing by inference” here since the data layer code is being reused in the test. However, it drastically reduces the amount of test code that needs to be written, and allows us to change the implementation of the data layer without changing our test code. These advantages outweigh the possibility of missed coverage.
Refactoring
 Once the code has been written for the Use Case and the tests are all passing, the developers can take some time to refactor their code. We must make a distinction here between rewriting and refactoring.
Once the code has been written for the Use Case and the tests are all passing, the developers can take some time to refactor their code. We must make a distinction here between rewriting and refactoring.
Refactoring is improving the structure of existing code without changing its functionality. The only way to do this is to have tests which validate the functionality of the code. Otherwise there is no way to tell if the functionality has been altered. The books Refactoring and Clean Code have some very helpful techniques for identifying “code smells” or common code issues and resolving them through careful application of refactoring patterns. You should read these books to really understand what refactoring is and how to do it effectively.
Measure
 Finally, we can use our toolchain to help measure the quality of our code. The tools that we built into our development pipeline, such as code coverage, style checking, static analysis, and others can give us a good indication of our code quality.
Finally, we can use our toolchain to help measure the quality of our code. The tools that we built into our development pipeline, such as code coverage, style checking, static analysis, and others can give us a good indication of our code quality.
Frequently Asked Questions
What if the client wants to use their own process?
Then we will use their process. This is most often true of Core Team projects. However, if we can make any suggestions about how to improve the client’s process, given experience with our own, then we should. Also, we are being hired as experts and our opinions matter. We should strive to be good consultants and try to help the client wherever we can.
What if I don’t know how to write testable code?
Your colleagues are here to help you! Ask someone with some more experience with TDD than you to help you. We all have different skillsets and we should learn from one another. Also, there are lots of different techniques for writing testable code that you can find online or in books.